
Technologien
Künstliche Intelligenzen
In den letzten fünf Jahren hat sich das neuromorphe Rechnen durch die Entwicklung modernster Hardware- und Softwaretechnologien rasant weiterentwickelt. Dabei ermöglicht die Nachahmung der Informationsverarbeitung von Tiergehirnen extrem energieeffiziente Rechenfähigkeiten – insbesondere für Edge-Geräte, also Geräte mit lokaler Datenverarbeitung. Helbling-Fachleute haben in diesem Bereich zuletzt in einem Projekt mit dem Partner Abacus neo umfangreiches interdisziplinäres Wissen aufgebaut. Im Fokus stand auch, wie das Potenzial neuromorphen Rechnens optimal genutzt werden kann.
Im Vergleich zu herkömmlichen digitalen neuronalen Netzen ermöglicht neuromorphes Rechnen eine höhere Energieeffizienz und geringere Rechenlatenz. Die Basis hierfür ist die Nachahmung natürlicher neuronaler Netzwerke im Gehirn von Tieren. So verwendet das neuromorphe Rechnen speicherinterne Berechnungen (Compute-in-Memory), eine besondere Codierung von Daten (sparse spike data encoding) oder beides. Dadurch eignet sich diese Technologie hervorragend für Anwendungen mit extrem niedrigem Energieverbrauch, insbesondere für solche, bei denen die Energiegewinnung aus der Umgebung gewonnen wird. Beispiele hierfür sind autonome, ständig einsatzbereite Geräte für die Umweltüberwachung, medizinische Implantate oder Wearables.
Derzeit wird die Einführung des neuromorphen Rechnens noch durch einige Aspekte begrenzt: die Reife der verfügbaren Hardware und Software-Frameworks, die begrenzte Anzahl von Anbietern und den Wettbewerb durch die laufende Entwicklung traditioneller Digitalgeräte. Ein weiterer Faktor ist der Widerstand konservativer Akteure aufgrund ihrer begrenzten Erfahrung mit der Theorie und praktischen Nutzung neuromorpher Geräte. Dabei braucht es aber eine neue Denkweise, um Probleme im Zusammenhang mit Hardware und Software anzugehen.
Angesichts der Vorteile wird das neuromorphe Rechen zu einer Schlüsseltechnologie für zukünftige energieeffiziente Edge-Anwendungen. Dementsprechend untersucht Helbling aktiv derzeit verfügbare Lösungen, um deren Eignung für eine breite Palette bestehender und neuer Anwendungen zu bewerten. Dabei kooperiert Helbling auch mit Partnern wie in einem laufenden Projekt mit Abacus neo, einem Unternehmen, das sich auf den Ausbau innovativer Ideen zu neuen Geschäftsmodellen konzentriert.
Herausforderung: Der Von-Neumann-Flaschenhals muss überwunden werden
Aktuelle Computerarchitekturen besitzen einen Hauptnachteil, sowohl in Bezug auf den Energieverbrauch als auch auf die Geschwindigkeit: Bei jedem Befehlszyklus (fetch-execute cycle) müssen Daten und Anweisungen zwischen dem Speicher und dem Prozessor (CPU) übertragen werden. Bei Von-Neumann-Geräten führt die grössere Länge und damit der höhere elektrische Widerstand dieser Kommunikationswege zu einem höheren Energieverlust in Form von Wärme. Tatsächlich wird oft mehr Energie für die Übertragung der Daten als für deren Verarbeitung durch die CPU verwendet. Da ausserdem die Datenübertragungsrate zwischen CPU und Speicher geringer ist als die Verarbeitungsrate der CPU, muss die CPU ständig auf Daten warten, was die Verarbeitungsrate des Systems begrenzt. In Zukunft wird dieser Von-Neumann-Flaschenhals noch restriktiver werden, da die Geschwindigkeiten von CPU und Speicher schneller zunehmen als die Datenübertragungsrate zwischen ihnen.
Neuromorphes Rechnen bringt Verarbeitung und Speicher zusammen
Neuromorphes Rechnen überwindet das Problem des Von-Neumann-Flaschenhalses und minimiert den Energieverlust durch Wärme, indem es keine Distanz mehr gibt zwischen Speicher und CPU. Bei diesen Nicht-von-Neumann-Architekturen mit Compute-in-Memory (CIM) werden Verarbeitung und Speicher zusammengelegt. Das ermöglicht extrem energieeffiziente und hochgradig parallele Datenverarbeitungsfunktionen. In der Praxis wurde dies durch die Entwicklung programmierbarer Crossbar-Arrays (CBA) erreicht: Effektiv sind dies Skalarprodukt-Prozessoren, die für Vektor-Matrix-Multiplikationsoperationen (VMM) optimiert sind – die grundlegenden Bausteine der meisten klassischen und Deep-Learning-Algorithmen. Diese Crossbars bestehen aus Datenleitungen am Eingang und Ausgang, wobei die Verbindungsstellen zwischen ihnen programmierbare Leitwerte haben, die auf spezifische algorithmische Aufgaben eingestellt werden können.
Daher wird bei einem neuromorphen Computer der Algorithmus durch die Architektur des Systems definiert und nicht durch die sequenzielle Ausführung von Anweisungen durch eine CPU. Um beispielsweise eine VMM durchzuführen, werden Spannungen (U), die den Vektor darstellen, auf die Datenleitungen am Eingang angelegt, während die Matrix durch die Leitwerte (G) des Crossbar-Arrays dargestellt wird. Das Ergebnis der VMM wird dann durch die Ströme (I) gegeben, die von den Datenleitungen am Ausgang fliessen (siehe Abbildung 1). Da eine VMM-Operation in einer taktlosen, asynchronen Weise sofort ausgeführt wird, sind die Latenzen und Verarbeitungszeiten wesentlich geringer als bei herkömmlichen Von-Neumann-Systemen.
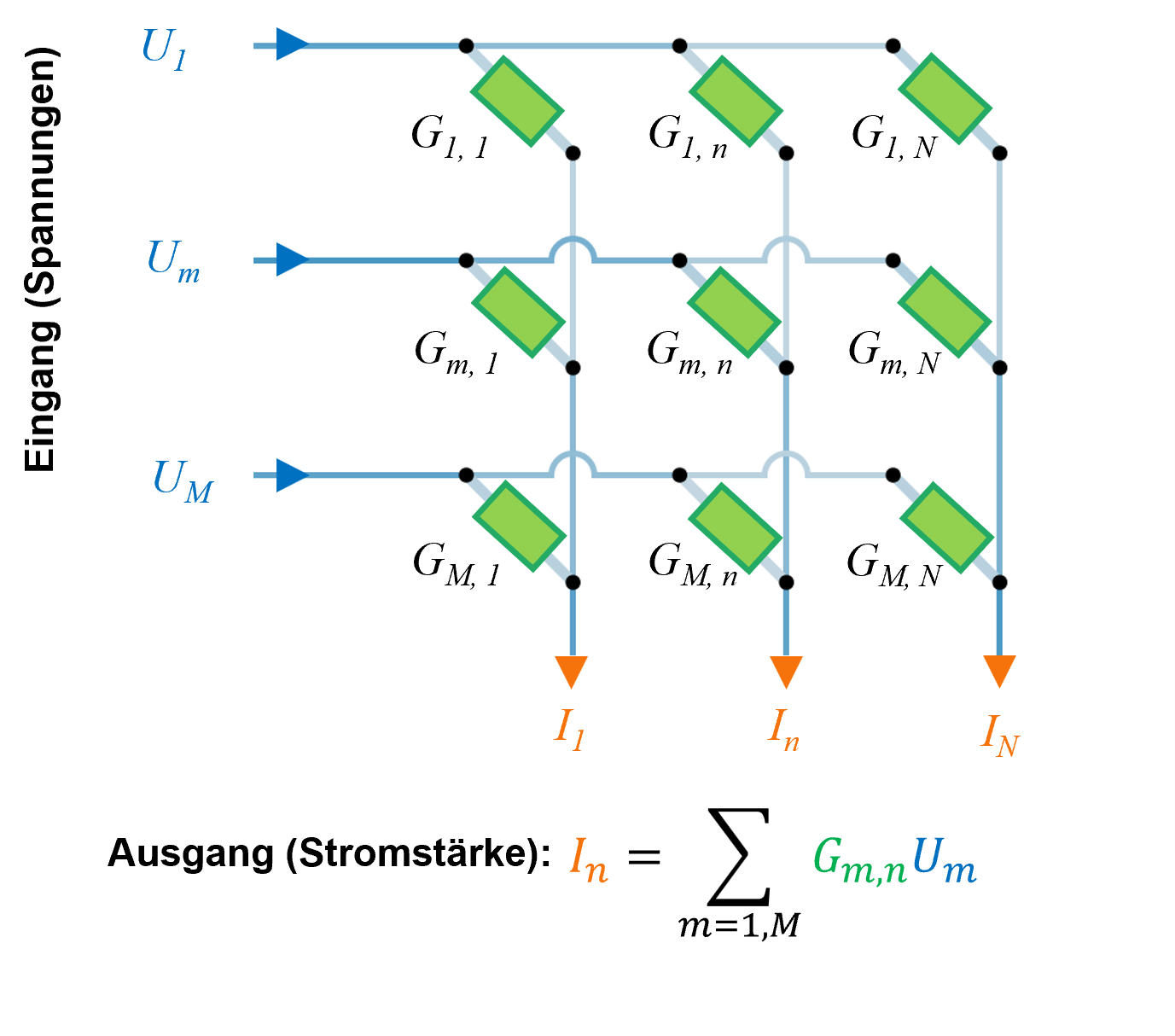

Die Energiekosten für die Implementierung einer Vektor-Matrix-Multiplikationsoperation auf einem CBA sind im Vergleich zu einem Von-Neumann-Baustein sehr gering: Energie wird nur für die Erzeugung der Eingangsspannungen und zur Überwindung der elektrischen Widerstandsverluste des CBA benötigt.
Ereigniskodierte Daten schaffen zeitdynamische Prozesse
Das zweite Hauptmerkmal des neuromorphen Rechnens ist sein zeitdynamischer Charakter und der Fluss spezieller ereigniskodierter Daten durch gepulste neuronale Netze, sogenannte Spiking Neural Networks (SNN).
Die Ereigniskodierung umfasst typischerweise die Umwandlung eines kontinuierlichen Signals in eine Folge repräsentativer kurzer analoger Pulse. Zu den Techniken gehört die Ratencodierung, bei der die Pulsfrequenz proportional zur momentanen Signalamplitude ist. Möglich sind auch zeitcodierte Pulse, die erzeugt werden, wenn ein Signal vordefinierte Schwellenwerte erfüllt. Die Vorteile dieser Darstellung sind der sehr geringe Energiebedarf für die Übertragung und die Möglichkeit, asynchrone, ereignisgesteuerte Systeme zu entwickeln.
Die Grundlage dieser neuronalen Netzwerke bilden auf der Hardware-Ebene implementierte Neuronen nach dem Modell Leaky-Integrate-and-Fire (LIF). Die Funktionsweise dieser LIF-Neuronen ist in Abbildung 3 dargestellt. Im Wesentlichen werden die in ein Neuron gelangenden Pulse mit der vortrainierten Gewichtung (w) ihrer jeweiligen Kanäle multipliziert. Diese werden dann integriert und zu einem Bias-Wert addiert, bevor sie zum momentanen Membranpotential (VM) dieses Neurons hinzugefügt werden. Dieses Membranpotential nimmt mit der Zeit ab, da es mit einer programmierbaren Rate sinkt, wodurch das Neuron eine Erinnerung an frühere pulscodierte Ereignisse erhält. Ist das Membranpotential grösser als ein vordefinierter Schwellenwert (VTH), feuert das Neuron einen Puls ab, bevor es auf seinen Grundzustand zurückgesetzt wird, um einen kontinuierlichen zeitdynamischen Prozess zu schaffen.

Neuromorphe Elemente müssen in Edge-Geräte integriert werden
In einem praktischen neuromorphen Gerät wird das CBA in einen neuromorphen Prozessor (NPU / Neuromorphic Processing Unit) mit vor- und nachgelagerten Signalverarbeitungsbausteinen integriert, um die Eingangspulse zu kodieren und die Ausgangspulse zu dekodieren (siehe Abbildung 4). Zu bedenken ist jedoch, dass die Natur dieser Signalverarbeitungsbausteine die Gesamtleistung des Systems stark beeinflusst und alle Energie- oder Latenzvorteile, die durch die Verwendung eines neuromorphen Rechenkerns gewonnen werden, eliminieren kann. Ihre Wahl ist entscheidend für die gesamte Effektivität einer neuromorphen Lösung.
So sind beispielsweise der Energieverbrauch und die Latenz typischer Mikrocontroller viel höher als bei einem CBA, was dessen Eignung einschränkt. Idealerweise sollte die Erzeugung von Eingangspulsen rein analog erfolgen oder auf den Sensoren durchgeführt werden, bevor sie auf die Datenleitungen des CBA angewendet werden. Eine interessante Lösung ist die Sensordatenfusion während der vorgelagerten Datenaufbereitung. Dabei wird die Dimensionalität der kombinierten Multisensordaten reduziert und es werden nur relevante Merkmale verarbeitet. Dies ist besonders vorteilhaft, wenn die Anzahl der Datenleitungen am Eingang des CBA begrenzt ist.

Zusammenfassung: Neuromorphes Rechnen hat ungenutztes Potenzial für zukünftige Technologien
Aufgrund ihrer Charakteristik bietet die neuromorphe Datenverarbeitung enorme Vorteile gegenüber herkömmlichen Geräten mit Von-Neumann-Architekturen. Zu den Vorteilen gehören sehr niedrige Latenzen und ein extrem niedriger Energiebedarf. Doch dessen Potenzial ist aus vielen Gründen noch lange nicht ausgeschöpft. Helbling-Experten sind überzeugt, dass diese Technologie für zukünftige Anwendungen etwa in den Bereichen MedTech oder Systemüberwachung entscheidend sein wird. Daraus können innovative Anwendungen resultieren und auf Basis neuer Konzepte nachhaltige Produkte und Geschäftsmodelle entstehen. Mit dieser Expertise und auch im Rahmen einer Partnerschaft mit Abacus neo positioniert sich Helbling als Industriepartner und Wegbereiter.
Autoren: Navid Borhani, Matthias Pfister
Hauptbild: Copilot



